[ad_1]
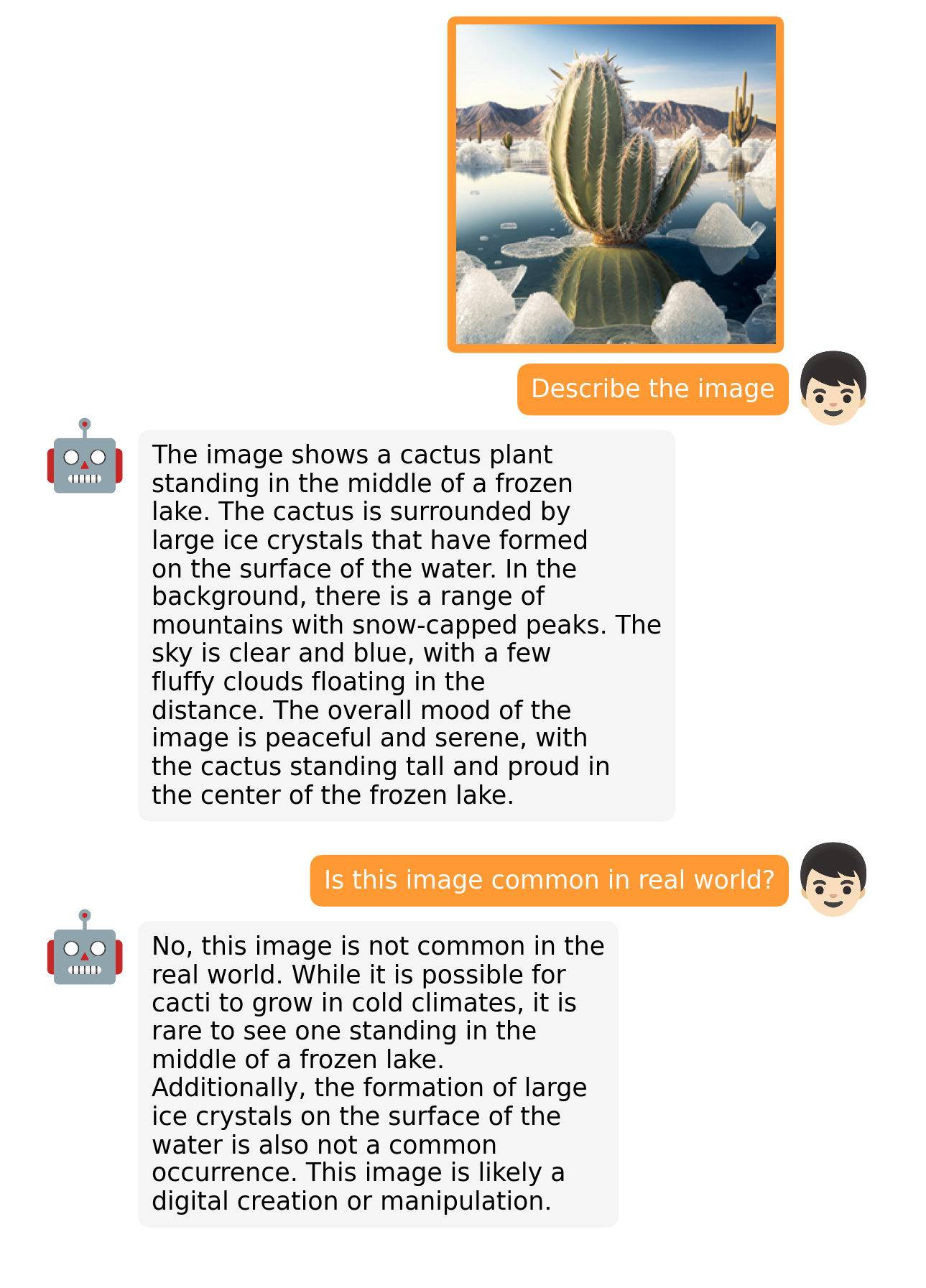
GPT-4 is the latest Large Language Model that OpenAI has released. Its multimodal nature sets it apart from all the previously introduced LLMs. GPT’s transformer architecture is the technology behind the well-known ChatGPT that makes it capable of imitating humans by super good Natural Language Understanding. GPT-4 has shown tremendous performance in solving tasks like producing detailed and precise image descriptions, explaining unusual visual phenomena, developing websites using handwritten text instructions, and so on. Some users have even used it to build video games and Chrome extensions and to explain complicated reasoning questions.
The reason behind GPT-4’s exceptional performance is not fully understood. The authors of a recently released research paper believe that GPT-4’s advanced abilities may be due to the use of a more advanced Large Language Model. Prior research has shown how LLMs consist of great potential, which is mostly not present in smaller models. The authors have thus proposed a new model called MiniGPT-4 to explore the hypothesis in detail. MiniGPT-4 is an open-source model capable of performing complex vision-language tasks just like GPT-4.
Developed by a team of Ph.D. students from King Abdullah University of Science and Technology, Saudi Arabia, MiniGPT-4 consists of similar abilities to those portrayed by GPT-4, such as detailed image description generation and website creation from hand-written drafts. MiniGPT-4 uses an advanced LLM called Vicuna as the language decoder, which is built upon LLaMA and is reported to achieve 90% of ChatGPT’s quality as evaluated by GPT-4. MiniGPT-4 has used the pretrained vision component of BLIP-2 (Bootstrapping Language-Image Pre-training) and has added a single projection layer to align the encoded visual features with the Vicuna language model by freezing all other vision and language components.
MiniGPT-4 showed great results when asked to identify problems from picture input. It provided a solution based on provided image input of a diseased plant by a user with a prompt asking about what was wrong with the plant. It even discovered unusual content in an image, wrote product advertisements, generated detailed recipes by observing delicious food photos, came up with rap songs inspired by images, and retrieved facts about people, movies, or art directly from images.
According to their study, the team mentioned that training one projection layer can efficiently align the visual features with the LLM. MiniGPT-4 requires training of just 10 hours approximately on 4 A100 GPUs. Also, the team has shared how developing a high-performing MiniGPT-4 model is difficult by just aligning visual features with LLMs using raw image-text pairs from public datasets, as this can result in repeated phrases or fragmented sentences. To overcome this limitation, MiniGPT-4 needs to be trained using a high-quality, well-aligned dataset, thus enhancing the model’s usability by generating more natural and coherent language outputs.
MiniGPT-4 seems like a promising development due to its remarkable multimodal generation capabilities. One of the most important features is its high computational efficiency and the fact that it only requires approximately 5 million aligned image-text pairs for training a projection layer. The code, pre-trained model, and collected dataset are available
Check out the Paper, Project, and Github. Don’t forget to join our 19k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at [email protected]
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
[ad_2]
Source link